


近年、急速に発展する生成AI技術。私たちの生活における存在感もますます大きくなっているように思える。そもそも生成AIとは何なのか。そしてこの新しい技術が何をもたらすのか。情報法を専門とする山口いつ子教授(東大大学院情報学環)への取材を通し、生成AIと社会の調和の方向性について探る。(取材・曽出陽太)
※AIに関する東大の動きについてはこちら
【AI×東大〜AIに東大はどう向き合うか〜】 東大新聞オンライン掲載記事まとめ(随時更新)
「ツール」としての生成AI
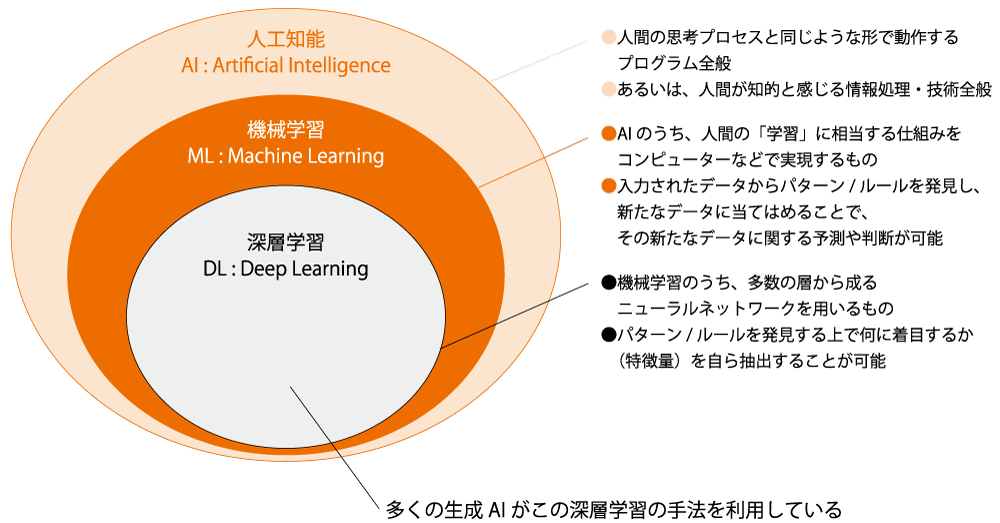
生成AIはAI(人工知能)と呼ばれる技術の一部分を指して用いられる語であり、明確な定義はないが「文章、画像、プログラム等を生成できるAIモデルにもとづくAIの総称を指す」(総務省・経産省『AI事業者ガイドライン』)などと定義されている例が見られる(図1)。深層学習といった新しい手法の開発を背景に近年めざましい発展を遂げており、生成物に対する責任の所在などの諸問題について社会がどう向き合うかを決めるべき時期を迎えているとも言える。山口教授は現状の生成AIは「人間が目的を設定し」開発されたツールであると指摘し、新しい技術に対し社会が今までどう向き合ってきたかを考えることがヒントになると話す。活版印刷術やテレビ、インターネットといった革新的な情報技術が生まれたとき、試行錯誤の中で技術の活用法や守るべき規範が形作られてきた。生成AIをとりまく現在の環境はまさにその試行錯誤の最中であるという。
生成AIが抱えるリスク
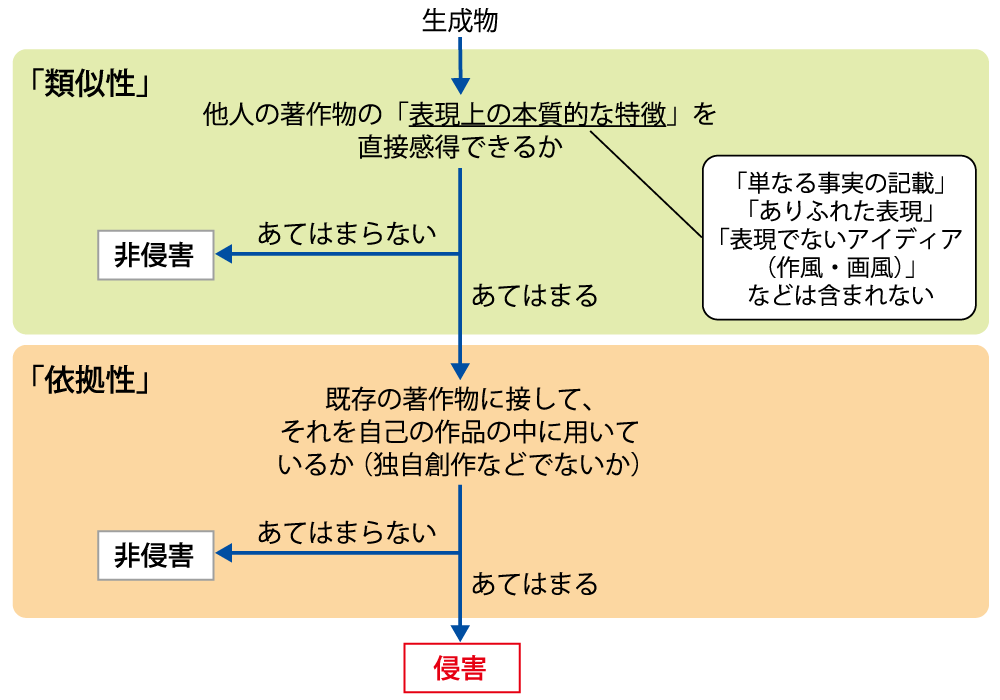
生成AIに付きまとう問題の一つに、著作権侵害のリスクが挙げられる。文章や画像、音楽といった著作物の著作者の権利は法律により一定の保護を受けている。しかし、生成AIによる生成物は、既存の著作物との関係で類似性と依拠性があるとされれば、著作権侵害になりうる(図2)。生成AIの開発過程における学習データとして著作物を利用することが、どこまで許容されるかについても、社会的な合意が得られていない。山口教授は、まずは生成AIによる「学習」と「生成」のプロセスにおける争点を個別に考えていく必要性を強調する。
「学習」に関する争点が注目される事例として、山口教授は2023年に米国大手新聞社ニューヨーク・タイムズ社(NYT)がChatGPTを開発するOpenAI社と、同社と提携関係にあるMicrosoft社を相手取った訴訟を挙げる。OpenAIが生成AIの学習データとして自社の記事を無許諾で利用したことを、著作権侵害として特に問題視したものだ。NYTが訴訟で主張する損害額は数千億円にのぼり、25年1月現在も係争が続いている。OpenAI側は生成AIの学習にかかる著作物の利用はフェアユースであると主張している。フェアユースとは米国の著作権法で定められた概念であり、そこでは一定の判断基準のもとで公正と認められる利用であれば、著作権者の許諾なしに著作物を利用できる。報道や研究目的の利用はフェアユースとされるが、生成AIの学習への利用については、金銭的な解決も含め今後の裁判所の判断が重要となると言う。一方日本の著作権法ではフェアユースにあたる包括的な権利制限規定は存在せず、著作物を許諾なく利用できる条件が個別に列挙されている。そこでは生成AIの学習のための利用が一定の場合に認められている。しかし、「学習」は合法であっても「生成」プロセスで著作権法上の問題が発生する可能性はある。
それでは「生成」において問題となる争点は何だろうか。一般的に生成AIは人間が与える指示を基に文章、画像などを生成するが、生成物が著作権や人格権といった他人の権利を侵害するようなものとなる可能性がある。例えば文章を生成する大規模言語モデル(LLM)の出力を参考にレポートを書いたとする。LLMは直接的に学習データを基に文章を生成するわけではないが、学習データに利用された著作物に類似した文章が生成されれば、剽窃として扱われてしまうかもしれない。東大は授業における生成AIの利用を一律には禁止していないが、生成AIを利用してレポートを書くならその責任は学生が負わなければならない。
生成AIを組み込んだサービスの提供者が定める利用規約には、利用者側が違法行為や権利侵害をしないよう求めたうえで、利用者側が行うAIの出力に関してサービス提供者は責任を負わないと明記されている例もある(図3)。山口教授はその種の免責条項は珍しくはないが、生成AIを開発しサービスを提供する市場で寡占的地位にある巨大企業から同意を求められれば、一利用者に交渉の余地は少なく、そこに力の不均衡があると指摘する。
生成AIのような「ツール」をめぐる責任の所在が問われた日本の事例として、Winny事件が知られている。インターネットの普及が急速に進んだ2000年代、「Winny」という匿名性の高いファイル共有ソフトが、映画や音楽などの違法コピーの共有に使われ社会問題となっていた。利用者の数が膨大となり、Winny事件ではツールであるWinnyの開発者が利用者による著作権侵害を幇助(ほうじょ)した責任として一度は有罪とされたものの、最高裁で無罪が確定した。生成AIとWinnyの争点の単純な同一視はできないが、今後生成AIの「学習」と「利用」に伴う責任やリスクを社会の中で誰がどこまで負うかが一層複雑な問題になると、山口教授は話す。
しかし、権利の問題で争うばかりではなく、AIの開発者、サービス提供者、利用者、そしてクリエイター等のステークホルダーが助け合ってイノベーションを起こしていくことが大切だということを忘れてはならない。
生成AIが抱えるリスクは著作権関係のものに限らず、多くの個人向けの生成AIサービスでは、利用者が入力した情報がAIの学習に利用される可能性がある。情報の取扱いに注意しなければ、プライバシーや営業秘密に関する極めてデリケートな情報がAIに学習され、間接的な流出のリスクにさらされるかもしれない。このように、生成AIは多くのリスクを抱えている。そこで重要なのが適切に生成AIを活用するためのルール作りということになる。
ルール形成で新しい技術に向き合う
生成AIの利用がますます一般的になっているほか、新しいプレイヤーが文章、画像、音楽などの創作に参入している。文章生成AIを利用した小説が発表されたり、画像生成AIによって生成したイラストの投稿が増加したりしている。正しく使えばとても役に立つツールである一方で、責任の所在を明確にする必要があると考えられる。しかし、そのやり方によってはイノベーションを萎縮させかねないと言う。例えばAIの学習データを利用することに対して過度な規制を課せば、開発に必要な学習データを十分に用意できず、研究開発が停滞してしまう可能性がある。一方で自分の作品が学習に利用され、類似した作品が生成できるようになることで不利益を被るクリエイターや、与信審査などにおいてAIによる判断によって不当な差別が生まれる懸念も大きい。山口教授は、イノベーションを促進しながら、社会の中で弱い立場にある個人に不均衡な負担をかけて置いていかないように考えて、ルールを作る必要があると言う。
各国が規制に向けて動き出しているが、AI開発企業が多く所在する米国のほかに、巨大な市場を有するEU(欧州連合)の影響力が大きい。EUによる規制にはほとんどのグローバル企業が従うため、EUの規制が実質的に世界標準となることが多い。この効果を「ブリュッセル効果」と呼び、GDPR(EUが定めた一般データ保護規則)や工業製品の規格(EUはスマートフォンの充電端子としてUSB−Cを採用することを義務付けている)にこの効果が見られる。そんなEUは2024年にAIを包括的に規制する法を定めた。一方日本でも政府がAIに関するルール形成を行う取り組みを進めている。しかし、山口教授はルール形成というのは法令を制定して終わりということではないと強調する。AIの開発や利用をモニタリングし、バランスの取れたルールを形成するための継続的なチェックが欠かせないと言う。実際、マスメディアやインターネットといった情報技術が出現するたびに、社会制度や法は変化を繰り返してきた。インターネット上の誹謗中傷(ひぼうちゅうしょう)の発信者を特定できるように情報開示請求手続を簡略化した法改正は記憶に新しい。
利用者に求められる「知識」と「コントロール」
それでは、私たちは生成AIとどのように付き合っていけば良いのだろうか。山口教授によると、利用者がAIについて問題意識を持つことがやはり重要になる。生成AIという新しい技術のポテンシャルを生かせるよう、健全な利用に繋げていくべきということだろう。山口教授は技術開発者やサービス提供者に限らず利用者にも大切な二つのポイントがあると話す。それは「知識/認識」と「コントロール」であり、前者は生成AIについて知識やリテラシーを身に付けること、後者は生成AIをツールとして適切な方法で利用することを指す。利用者が身に付けるべき「知識」とは、生成AIの基本的な仕組みや生成AIによる「生成」に伴うリスクを理解することだといえる。生成物が他人の権利を侵害する可能性やプライバシーに関わるデータの流出といった前述したリスクについて認識したうえで、安全に利用できるよう努める必要がある。
生成AIを使うときに自分がどのような行為をしているかを把握し、出力をどのように利用するかを決めるのが、利用者にとって大切となる「コントロール」である。生成AIはその特性上、誤った情報や差別的な表現を出力する可能性があるが、不適切な出力をうのみにして利用してしまった際に名誉毀損(きそん)などの責任を負うのは利用者だ。だからこそ、AIを利用者自身がコントロールし、その出力を使用すべきかどうかを判断するなど、主体的な利用をしなければならない。
前述したように、生成AIを安全に、そして効果的に活用するためのルールの形成が進められている。しかし、著作権侵害などの問題に関してはどこまでの利用が許されるのかといった線引きがはっきりしていないことも多い。山口教授は理想論ではあるとしたうえでも、利用者が客観的な視点を持ち、賢くAIを利用するための智慧(ちえ)と能力を積極的に身に付ける姿勢が必要だと語る。
より良い方向への活用を
生成AIは発展途上の技術であり、今後私たちの生活のさらに深い場所に組み込まれることだろう。確かに生成AIにはさまざまな課題がある。しかし、山口教授は「より良いものを創り出すという考え方は重要だと思っています。今までになかったツール、より便利な技術を、英知を尽くして開発し、社会をより良い方向に導くために変化を促すという意識は、誰もが共有できると思います」と話す。多大な資金と労力をかけてまで生成AIの開発が行われている理由もそこにあり、生成AIがさらなるイノベーションの基礎となったり、人間による創作の可能性を広げたりすると期待されているのだ。
山口教授は東大の学生の多くが技術開発やルール形成に携わるだろうと話し、学生に向けてエールを送る。「技術と社会の調和のために、社会で期待される役割を担う立場にあれば、苦労も多いと思いますが、プライドを持って活動してもらえるといいなと心から願います」








